We have covered the features behind the hours prices in the EDA post (link.) In this post, we will use a classic (statistical) Machine Learning technique – Multiple Regression – to predict the prices.
First, let’s load the necessary packages and create the theme for the charts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
##### Load Libraries ##### library(dplyr) library(ggplot2) library(car) library(forecast) library(gridExtra) ##### Theme Moma ##### theme_moma <- function(base_size = 12, base_family = "Helvetica") { theme( plot.background = element_rect(fill = "#F7F6ED"), legend.key = element_rect(fill = "#F7F6ED"), legend.background = element_rect(fill = "#F7F6ED"), panel.background = element_rect(fill = "#F7F6ED"), panel.border = element_rect(colour = "black", fill = NA, linetype = "dashed"), panel.grid.minor = element_line(colour = "#7F7F7F", linetype = "dotted"), panel.grid.major = element_line(colour = "#7F7F7F", linetype = "dotted") ) } |
The train dataset contains 81 features that can be utilized for machine learning except ‘Id.’ So I’ll just get rid of it and also set up a new dataset.
|
1 2 |
##### Creating Train Dataset ##### ml <- select(train, - Id) |
One interesting thing about this dataset is that there are many categorical variables with NAs. Let’s see…
|
1 2 |
##### Where Are NAs? ##### colSums(sapply(ml, is.na)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
> colSums(sapply(ml, is.na)) MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour 0 0 259 0 0 1369 0 0 Utilities LotConfig LandSlope Neighborhood Condition1 Condition2 BldgType HouseStyle 0 0 0 0 0 0 0 0 OverallQual OverallCond YearBuilt YearRemodAdd RoofStyle RoofMatl Exterior1st Exterior2nd 0 0 0 0 0 0 0 0 MasVnrType MasVnrArea ExterQual ExterCond Foundation BsmtQual BsmtCond BsmtExposure 8 8 0 0 0 37 37 38 BsmtFinType1 BsmtFinSF1 BsmtFinType2 BsmtFinSF2 BsmtUnfSF TotalBsmtSF Heating HeatingQC 37 0 38 0 0 0 0 0 CentralAir Electrical X1stFlrSF X2ndFlrSF LowQualFinSF GrLivArea BsmtFullBath BsmtHalfBath 0 1 0 0 0 0 0 0 FullBath HalfBath BedroomAbvGr KitchenAbvGr KitchenQual TotRmsAbvGrd Functional Fireplaces 0 0 0 0 0 0 0 0 FireplaceQu GarageType GarageYrBlt GarageFinish GarageCars GarageArea GarageQual GarageCond 690 81 81 81 0 0 81 81 PavedDrive WoodDeckSF OpenPorchSF EnclosedPorch X3SsnPorch ScreenPorch PoolArea PoolQC 0 0 0 0 0 0 0 1453 Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice 1179 1406 0 0 0 0 0 0 |
We know that there are 1453 NAs in PoolQC feature. How many valid datadpoints does PoolQC have?
|
1 2 3 |
##### Valid Data Points ##### table(ml$PoolQC) sum(is.na(ml$PoolQC)) |
|
1 2 3 4 5 6 |
> table(ml$PoolQC) Ex Fa Gd 2 2 3 > sum(is.na(ml$PoolQC)) [1] 1453 |
So, there are only seven valid data points: 2Ex, 2Fa, and 3Gd.
We sure can get rid of the feature altogether as it seems like the majority of the data doesn’t have a pool. But what if having a pool is statistically significant? Also, not to mention that many other features might be in the same situation as PoolQC.
So, here is what we are going to do. We will add “None” as another level in the factor variable.
|
1 2 3 4 5 6 7 8 9 10 |
##### Add NONE in Factor ##### for(i in names(ml)) { if(class(ml[[i]]) == "factor"){ levels <- levels(ml[[i]]) levels[length(levels) + 1] <- "N/A" ml[[i]] <- factor(ml[[i]], levels = levels) ml[[i]][is.na(ml[[i]])] <- "N/A" } } |
The code will loop through every feature and see if it is a factor variable. If yes, it will change from NA to “None” which will be treated as another legitimate level.
Now let’s see again if we have any NA.
|
1 2 |
##### Any NAs Left? ##### sum(is.na(ml)) |
|
1 2 |
> sum(is.na(ml)) [1] 348 |
Oh okay, there are still some NAs. But where are they from?
|
1 2 |
##### The Final NAs ##### colSums(sapply(ml, is.na)) |
|
1 2 3 4 5 6 7 8 |
> ##### The Final NAs ##### > colSums(sapply(ml, is.na)) MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour 0 0 259 0 0 0 0 0 MasVnrType MasVnrArea ExterQual ExterCond Foundation BsmtQual BsmtCond BsmtExposure 0 8 0 0 0 0 0 0 FireplaceQu GarageType GarageYrBlt GarageFinish GarageCars GarageArea GarageQual GarageCond 0 0 81 0 0 0 0 0 |
Okay, so it is from LotFrontage, MasVnrArea, and Garage Year Built. Those two are easy enough. According to the definition, LotFrontage is Linear feet of street connected to the property. If it is NA, that means a property is not connected to the street. So, I’ll just change it to zero. As for MasVnrArea, its definition is Masonry veneer area in square feet. If it is NA, that means it is 0. So for these two, I’ll just change from NA to zero.
|
1 2 3 4 5 6 7 |
#LotFrontage is legitimate as it is not connected. So we will change that to 0 ml <- ml %>% mutate(LotFrontage = ifelse(is.na(LotFrontage),0,LotFrontage)) #MasVnrArea: Masonry veneer area in square feet, so we will change to 0 ml <- ml %>% mutate(MasVnrArea = ifelse(is.na(MasVnrArea),0,MasVnrArea)) |
We still have GarageYrBlt. Hmm, This one is interesting. It is numeric and those with 0 likely means they don’t have a garage. We could also convert the feature to factor variable, but when we run the regression, yikes, there will be ten plus features, and if they were to be significant, we could kiss goodbye to our dear parsimony. Therefore, in this case, I’ll just drop GarageYrBlt. 🙂
|
1 2 3 |
##### Removing Rows ##### ml <- ml%>% filter(is.na(GarageYrBlt) == "FALSE") |
Next, I’ll split them to train and test sets.
|
1 2 3 4 5 6 7 |
##### Splitting ##### size <- floor(0.75*nrow(ml)) set.seed(123) train_index <- sample(seq_len(nrow(ml)), size = size) ml_train <- ml[train_index,] ml_test <- ml[-train_index,] |
Alright, let’s start by building the models using Forward, Both, and Stepwise.
|
1 2 3 4 |
##### Run the LMs ##### forward <- step(lm(data = ml_train, SalePrice ~ .), direction="forward") stepwise <- step(lm(data = ml_train , SalePrice ~ .), direction="both") backward <- step(lm(data = ml_train , SalePrice ~ .), direction="backward") |
It is going to take some time depending on the CPU power. Let’s take a look at AIC which measures the complexity of the model.
|
1 2 3 4 |
##### AIC ##### AIC(forward) AIC(stepwise) AIC(backward) |
|
1 2 3 4 5 6 7 |
> ##### AIC ##### > AIC(forward) [1] 23610.66 > AIC(stepwise) [1] 23511.07 > AIC(backward) [1] 23512.23 |
We can see that Stepwise and Backward methods’ AICs are pretty close 23,511 and 23,512. Next, let’s take a look at RMSE.
|
1 2 3 4 |
##### Accuracy ##### accuracy(forward) accuracy(stepwise) accuracy(backward) |
|
1 2 3 4 5 6 7 8 9 |
> accuracy(forward) ME RMSE MAE MPE MAPE MASE Training set 6.43103e-13 17398.95 11769.18 -0.4030633 6.760592 0.2169911 > accuracy(stepwise) ME RMSE MAE MPE MAPE MASE Training set -2.793553e-13 18106.3 12348.76 -0.4217125 7.128347 0.2276768 > accuracy(backward) ME RMSE MAE MPE MAPE MASE Training set -3.694822e-13 18064.01 12335.01 -0.4169436 7.115912 0.2274234 |
Again, Stepwise’s and Backward’s RMSEs are close again. What about Adjusted R-Square and overall fit of the models?
|
1 2 3 4 |
##### Summary ##### summary(forward) summary(stepwise) summary(backward) |
I’ll show only a portion of the results.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Forward Residual standard error: 19870 on 793 degrees of freedom Multiple R-squared: 0.9427, Adjusted R-squared: 0.9253 F-statistic: 54.32 on 240 and 793 DF, p-value: < 2.2e-16 Stepwise Residual standard error: 19580 on 884 degrees of freedom Multiple R-squared: 0.9379, Adjusted R-squared: 0.9274 F-statistic: 89.6 on 149 and 884 DF, p-value: < 2.2e-16 Backward Residual standard error: 19570 on 881 degrees of freedom Multiple R-squared: 0.9382, Adjusted R-squared: 0.9275 F-statistic: 87.97 on 152 and 881 DF, p-value: < 2.2e-16 |
I mean, seriously, they aren’t that different. What we should do next is to take a look at various plots, but to make things easier I’ll just do one which is Stepwise.
|
1 2 |
##### Assessing Plots ##### plot(stepwise) |
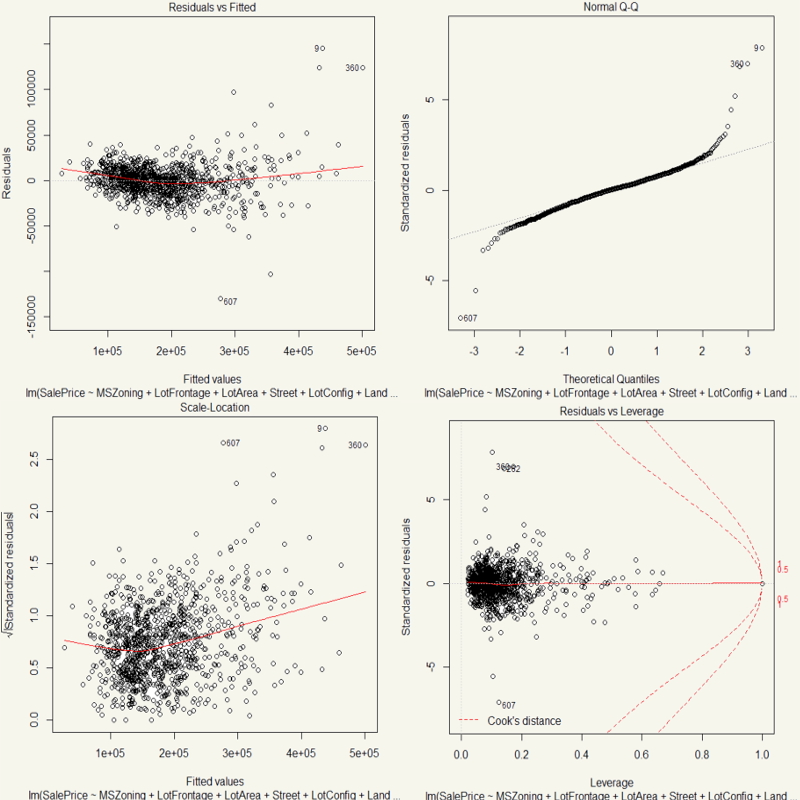
Well, they are mostly quite okay. Most of the points in QQ Plot are on the diagonal line. Most of the data points have small Cook’s D. Heteroscedasticity is quite held as the shape is quite even.
The plot() function has done a great job giving us the essential charts. But I’d like to see the leverage in another form.
|
1 2 3 4 5 6 7 8 9 |
##### Plotting Leverage Points ##### lev <- function(fit) { x <- length(coefficients(fit)) y <- length(fitted(fit)) plot(hatvalues(fit), main="Leverage") abline(h=c(2,3)*x/y, col="red", lty=2) } lev(fit=stepwise) |

Yeah, well, that is surely a whole lot of leverage points with value 1. That’s high! We sure can make it better. It is clear that there are outliers and high leverage data points in the dataset. I could chop them off. But I’ll employ log transformation.
|
1 2 |
##### Stepwise Log ##### stepwise_log <- step(lm(data = ml_train, log(SalePrice) ~ .), direction="both") |
Alright, let’s see the diagnostics.
|
1 2 3 4 |
##### Diagnostics ##### summary(stepwise_log) AIC(stepwise_log) accuracy(stepwise_log) |
|
1 2 3 4 5 6 7 8 9 |
Residual standard error: 0.08763 on 866 degrees of freedom Multiple R-squared: 0.9528, Adjusted R-squared: 0.9437 F-statistic: 104.7 on 167 and 866 DF, p-value: < 2.2e-16 > AIC(stepwise_log) [1] -1945.882 > accuracy(stepwise_log) ME RMSE MAE MPE MAPE MASE Training set -3.437951e-18 0.08019212 0.05778563 -0.00455692 0.4813528 0.1985712 |
Hm, 0.9436 Adjusted R-Squared, significant p-value, and -1945.451 AIC. That was a huge improvement. Let’s summarize the diagnostics from our four different models.
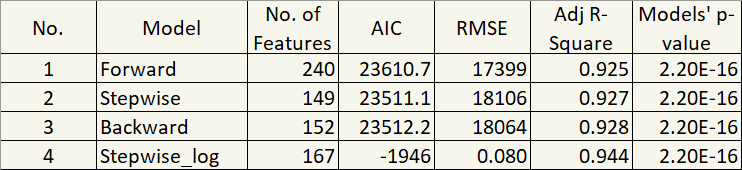
But one thing that stands out to me is 167 features. Ugh… They are bloated because many of them are factor variables. So, next improvement is to get rid of those that are not statistically significant. Luckily, R distinguishes that by the asterisk. So, I’ll just remove statistically insignificant features in the next model.
|
1 2 3 4 5 6 7 |
##### Log with Only Statistically Significant Features ##### stepwise_log_2 <- lm(data = ml_train , log(SalePrice) ~ MSSubClass+ MSZoning+ LotFrontage+ LotArea+ OverallQual+ OverallCond+ YearBuilt+ YearRemodAdd+ BsmtCond+ CentralAir+ X1stFlrSF+ X2ndFlrSF+ KitchenQual+ GarageCars+ WoodDeckSF+ OpenPorchSF+ ScreenPorch) |
Alright, let’s see the stats again.
|
1 2 3 4 |
##### Diagnostics ##### summary(stepwise_log_2) AIC(stepwise_log_2) accuracy(stepwise_log_2) |
|
1 2 3 4 5 6 7 8 9 |
Residual standard error: 0.1364 on 1008 degrees of freedom Multiple R-squared: 0.8668, Adjusted R-squared: 0.8635 F-statistic: 262.4 on 25 and 1008 DF, p-value: < 2.2e-16 > AIC(stepwise_log_2) [1] -1157.571 > accuracy(stepwise_log_2) ME RMSE MAE MPE MAPE MASE Training set -2.745699e-17 0.1346866 0.09267442 -0.01250119 0.7703479 0.318461 |
Okay, now it gets much less complicated! All Hail Parsimony!!! Ah, but that comes with a cost. RMSE is almost twice that of Stepwise_log model and adjusted R-square, for the first time, is below 0.90.
For now, I’d choose Stepwise_log_2 model. Now, let’s see the charts.
|
1 2 3 |
##### Plots ##### plot(stepwise_log_2) lev(fit = stepwise_log_2) |
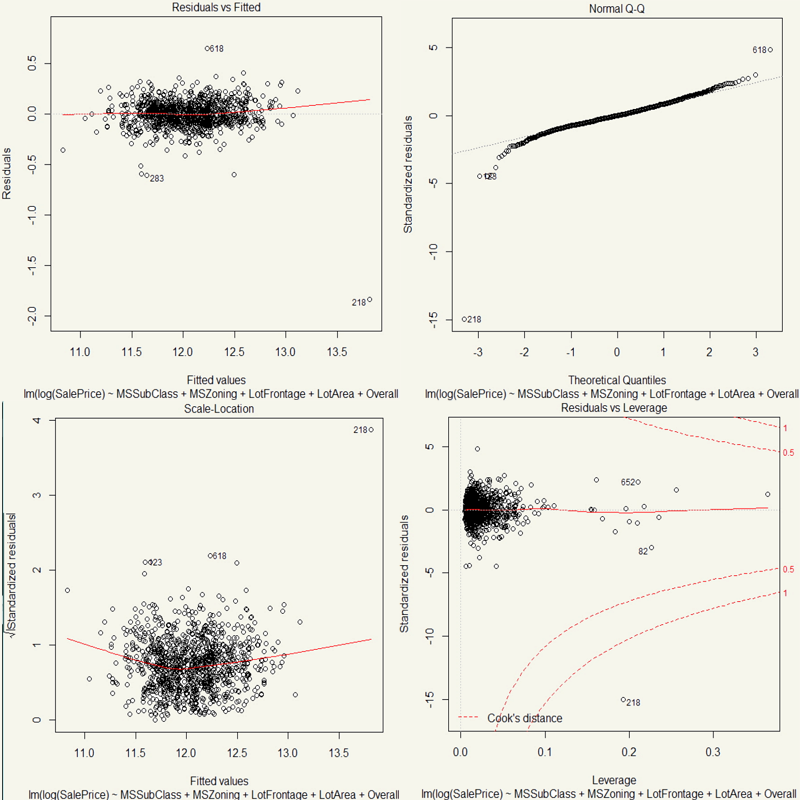
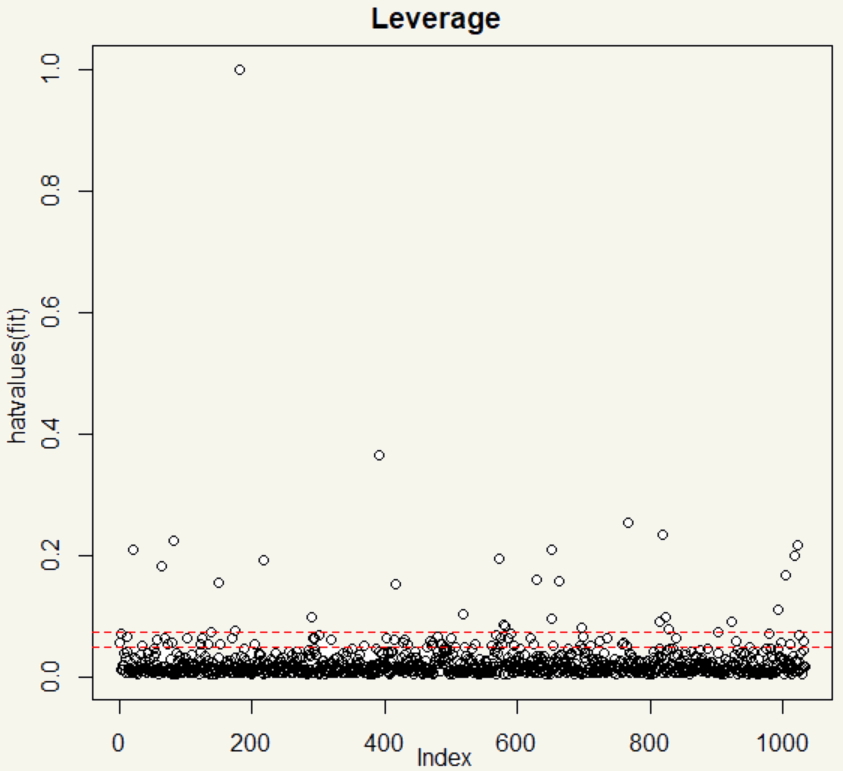
Nice. We did reduce the leverage point by, well, almost all by just simply taking a log. But still, there are a number of those leverage points around.
You know what, I’ll just run another model with the same features but excluding those leverage points.
|
1 2 3 4 5 6 7 |
##### Log, Staitstically Significant, Without Leverage ##### stepwise_log_3 <- lm(data = ml_train[-c(118,128,182,218,486,833),] , log(SalePrice) ~ MSSubClass+ MSZoning+ LotFrontage+ LotArea+ OverallQual+ OverallCond+ YearBuilt+ YearRemodAdd+ BsmtCond+ CentralAir+ X1stFlrSF+ X2ndFlrSF+ KitchenQual+ GarageCars+ WoodDeckSF+ OpenPorchSF+ ScreenPorch) |
Let’s see the stats.
|
1 2 3 4 |
##### Diagnostics ##### summary(stepwise_log_3) AIC(stepwise_log_3) accuracy(stepwise_log_3) |
|
1 2 3 4 5 6 7 8 9 |
Residual standard error: 0.1201 on 1003 degrees of freedom Multiple R-squared: 0.8964, Adjusted R-squared: 0.8939 F-statistic: 361.5 on 24 and 1003 DF, p-value: < 2.2e-16 > AIC(stepwise_log_3) [1] -1413.84 > accuracy(stepwise_log_3) ME RMSE MAE MPE MAPE MASE Training set -5.171113e-18 0.1186122 0.08839655 -0.009765258 0.7352925 0.304114 |
Okay, that’s good. Those leverage points distorted our prediction. Up to this point, there are six models.
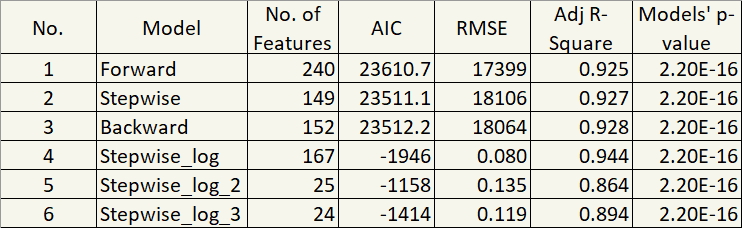
In term of Adjusted R-Square and RMSE, in my opinion, they aren’t that different. But they are significantly different, in term of parsimony. I mean, 240 features!?
And so it now comes down to the good old question: Predictive power or Parsimony?
I chose parsimony for Stepwise_log_3. 😊 Think about it in a different angle.
Comparing Stepwise_log_3’s 0.89 Adjusted R-Square to that of model 1 (0.93), it is only 0.04 apart. But the reduction in the number of features is 216. Well, for me, Stepwise_log_3 is the winner.
Now that we got our model, we need to make a real prediction on the test set. I’ll add them back to the test set for charts.
|
1 2 3 |
##### Predict ##### ml_test$log2 <- exp(predict(stepwise_log_2, newdata=ml_test)) ml_test$log3 <- exp(predict(stepwise_log_3, newdata=ml_test)) |
Let’s see how they look.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
##### Graph ##### log2 <- ggplot(ml_test, aes(y = SalePrice, x = log2, col = MSZoning)) + geom_point() + scale_y_continuous(labels = scales::dollar) + scale_x_continuous(labels = scales::dollar) + theme_moma() + theme(legend.position="none") + xlab("Stepwise_Log_2") + ggtitle("Stepwise_Log_2") log3 <- ggplot(ml_test, aes(y = SalePrice, x = log3, col = MSZoning)) + geom_point() + scale_y_continuous(labels = scales::dollar) + scale_x_continuous(labels = scales::dollar) + theme_moma() + theme(legend.position="none") + xlab("Stepwise_Log_3") + ylab("") + ggtitle("Stepwise_Log_3") grid.arrange(log2,log3,nrow = 1) |
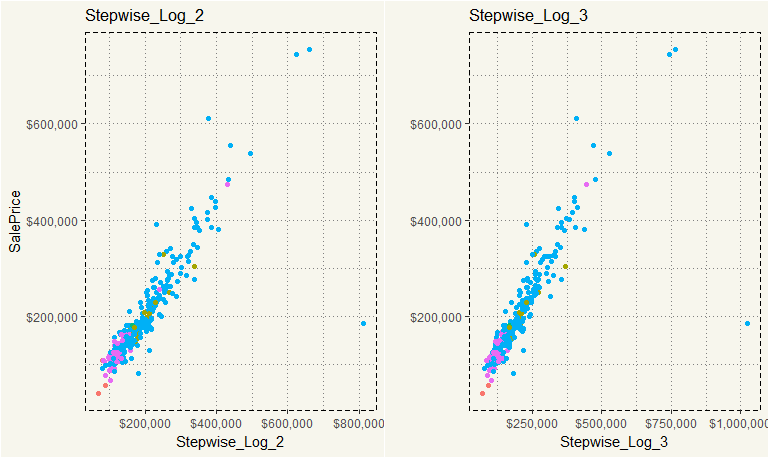
They are not that different at all, right? The overall shape is essentially the same. The difference is the outlier on the right in which Stepwise_Log_2 model forecasted $800,000, but Stepwise_Log_3 model predicted $1,000,000. I’d guess Stepwise_Log_3’s RMSE is more than that of Stepwise_Log_2.
|
1 2 3 4 5 6 7 |
##### RMSE ##### ml_test %>% select(SalePrice, log3, log2) %>% mutate(delta_2 = SalePrice - log2, delta_3 = SalePrice - log3) %>% summarise(RMSE_2 = sqrt((sum(delta_2^2))/345), RMSE_3 = sqrt((sum(delta_3^2))/345)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> ##### RMSE ##### > ml_test %>% + select(SalePrice, log3, log2) %>% + mutate(delta_2 = SalePrice - log2, + delta_3 = SalePrice - log3) %>% + summarise(RMSE_2 = sqrt((sum(delta_2^2))/345), + RMSE_3 = sqrt((sum(delta_3^2))/345)) # A tibble: 1 x 2 RMSE_2 RMSE_3 <dbl> <dbl> 1 45204.16 52801.3 |
Yep. No doubt. But I’m just curious, what would the delta look like if we were to exclude the outliers.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
##### Delta Plots ##### delta2 <- ml_test %>% mutate(delta = SalePrice - log2) %>% filter(delta > -600000) %>% ggplot(aes(y = SalePrice, x =delta, col = MSZoning)) + scale_y_continuous(labels = scales::dollar) + scale_x_continuous(labels = scales::dollar) + geom_point() + theme_moma() + xlab("Stepwise_Log_2 Delta") + theme(legend.position="none") + ggtitle("Stepwise_Log_2 Delta") delta3 <- ml_test %>% mutate(delta = SalePrice - log3) %>% filter(delta > -600000) %>% ggplot(aes(y = SalePrice, x =delta, col = MSZoning)) + scale_y_continuous(labels = scales::dollar) + scale_x_continuous(labels = scales::dollar) + geom_point() + theme_moma() + xlab("Stepwise_Log_3 Delta") + ylab("") + ggtitle("Stepwise_Log_3 Delta") + theme(legend.position="none") grid.arrange(delta2,delta3,nrow = 1) |
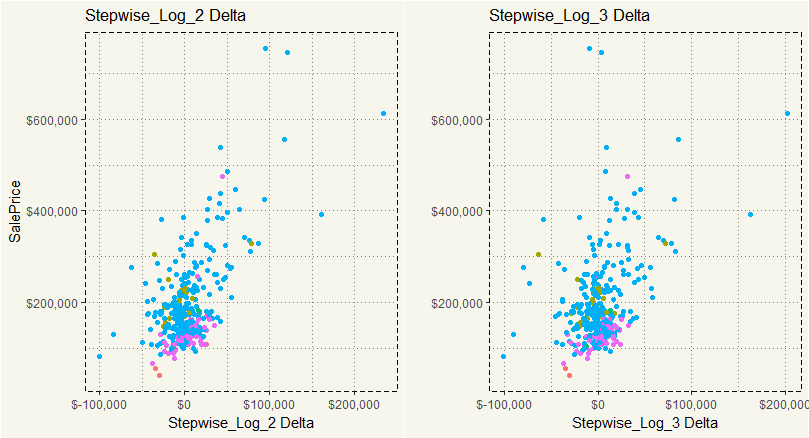
Yep, that is about the same.
TL;DR: Multiple Regression works well for predicting house prices. However, the tradeoff of parsimony and predictive accuracy exists. In this case, I chose parsimony.